KV Caching with vLLM, LMCache, and Ceph


Inference accounts for 90% of the machine learning costs for deployed AI systems, and it is no surprise that inference optimization is a burgeoning topic in the research community. IDC estimates that global enterprises will invest $307 billion on AI solutions in 2025, and that number is expected to grow aggressively year-over-year.
Understanding the workload
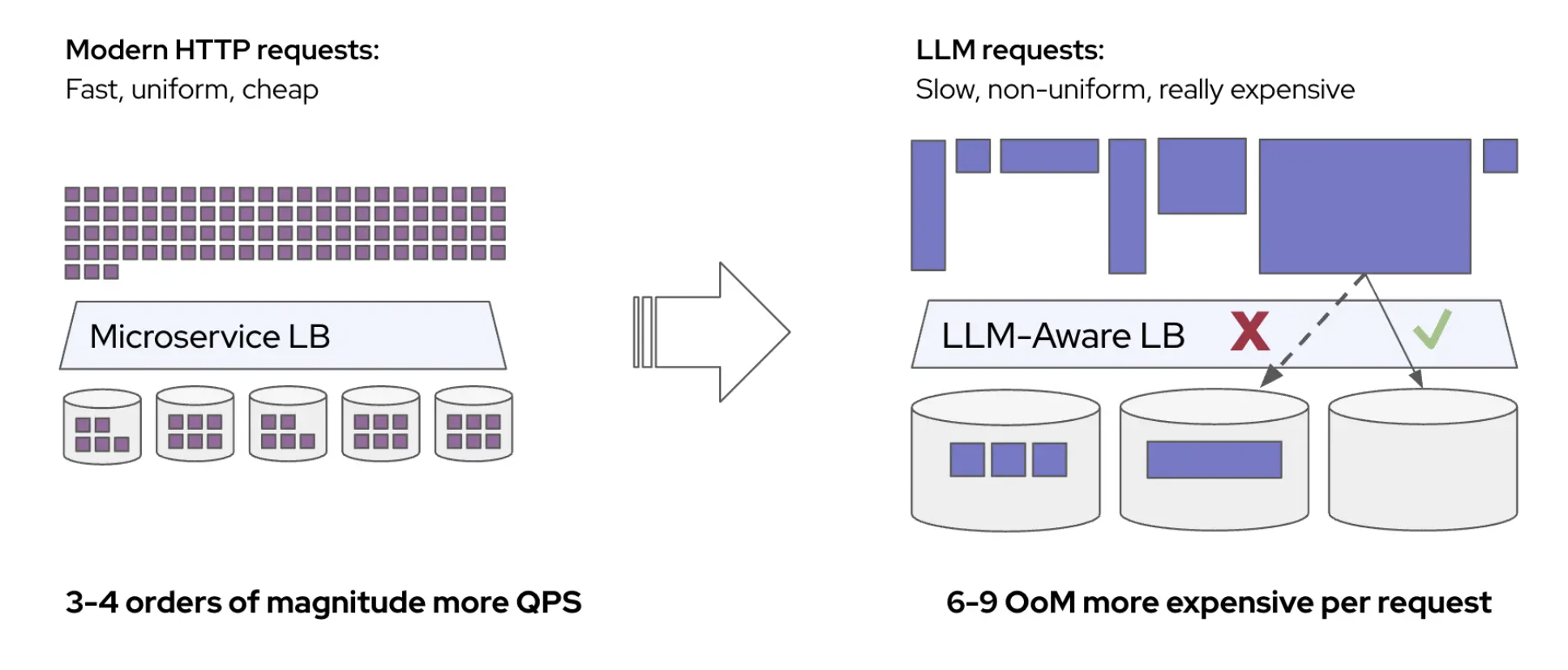
Unlike training, inference for autoregressive language models only involves the forward pass, which itself is broken up into two distinct phases: prefill and decode. Each phase has a unique workload profile – prefill tends to be computation bound, consuming every ounce of floating-point arithmetic capability the system can garner, followed by decode, which is principally limited by memory bandwidth. While the prefill phase can easily be parallelized across GPUs because all the tokens that represent the prompt are known once a request is sent to the model API, the computation grows quadratically with each additional token because key and value weights need to be updated across all layers. This complicates the deployment of inference services where context lengths are growing rapidly to accommodate larger code bases, longer documents, and retrieval augmented generation. KV caching is where the computed key and value weights that correspond with token sequences in a prompt are saved for later, and then retrieved when they are used in a subsequent prompt to avoid the cost of computation (GPU hours) and to reduce the time between when the prompt was submitted as a request and the first response token (time-to-first token, or TTFT).